
[Video] How GitHub Changed Their Approach to Processing 300 Million Pushes Every Day?
Get the key lessons that you can apply from GitHub's story

👋 Hi, this is Dishit with this week’s newsletter. I write about software engineering, clean code and developer productivity.
Remember, all subscribers can get their code reviewed. This newsletter will always be free. So go ahead and click on the Subscribe button.
If you have been following GitHub Engineering Blog, you would have seen how they changed their approach to processing 300 million daily pushes.
If not, help is here.
300 million pushes per day is significant, and it’s fascinating to see how they tackled the challenges associated with such a large volume of operations.
In this video, I’ll be going through the key points from the blog and discussing how you can apply the learnings to your day-to-day work.
It’s one thing to read about a company’s experience, but it’s another to understand how you can implement similar strategies in your own projects.
The blog highlighted the issues GitHub faced with their previous approach, where a monolithic process triggered by each push resulted in a sequence of 50+ tasks being executed.
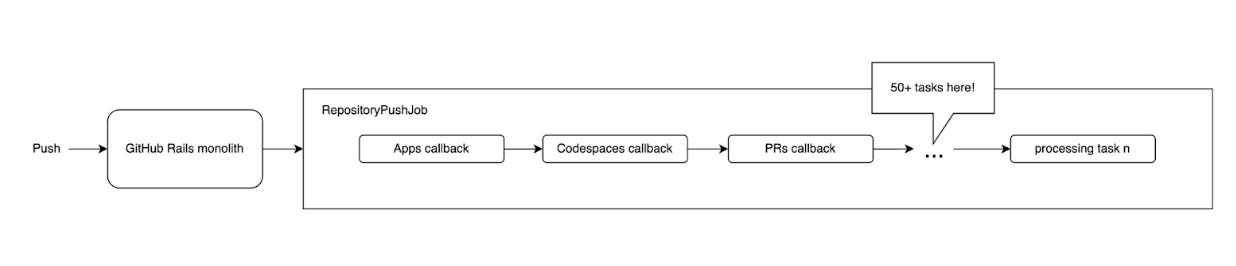
This sequential process led to increased latency, a higher risk of system failure, and difficulties in troubleshooting and testing.
To address these challenges, GitHub introduced Kafka to create a job queue bridge.
It split the monolithic job into multiple independent tasks that could be run in parallel.
This approach led to several advantages, including improved performance, easier troubleshooting, and the ability to scale specific tasks as needed.
So, how can you apply these lessons to your own work?
Even if you’re not dealing with the scale of GitHub, you may encounter similar issues with tightly coupled systems, complex classes, and difficult testing processes.
Here are some key takeaways:
Break down complex classes into smaller, more manageable pieces to make testing easier
Consider making tightly coupled systems asynchronous to improve performance and reduce waiting times
Break down large processes into modular components to simplify testing and maintenance
Implement retry mechanisms for integrations with multiple systems, but be mindful of the potential impact on system load and performance
It’s important to learn from the experiences of companies like GitHub and adapt their strategies to your own projects.
By addressing issues related to system complexity, testing, and performance, you can improve the overall reliability and efficiency of your own systems.
Have you faced similar challenges in your own work? How did you overcome them?
I’d love to hear about your experiences in the comments below.
And don’t forget to check out the original blog on the GitHub Engineering Blog for more in-depth information on their approach to processing 300 million pushes every day.
Before you go!
If you know someone who is looking to have their code reviewed for technical debts, code smell - look no further.
Help is here.
Just subscribe to this newsletter or reply to this email with word “REVIEW” and I will review your code.